





多くの人は、アジャイル型の製品開発を、主にソフトウェア開発と関連付けて考えます。 これは、アジャイルマニフェストと原則で、とりわけ「ソフトウェア」を参照しているためです。 ただし、アジャイルの価値観と原則は、より広く応用できます。 バイオテクノロジーから製造、マーケティングまで、アジャイルアプローチを使って製品を作成している業界はさまざまなです。 これが可能なのは、アジャイルなインフラストラクチャがあるからこそです。 この記事では、インフラストラクチャ部門がスクラムを使用してどのようにアジャイルになったかについて説明します。
背景と課題
多くのインフラ部門がそうであるように、この組織も従業員や顧客に提供するサービス(ハードウェア、ソフトウェア、ネットワーク、ストレージなど)を管理し、技術サポートを担当していました。 典型的なプロジェクトは、クラウドの移行からネットワークとストレージのアップグレード、多要素認証の展開にまで及びました。 また、オンサイトおよびオフサイトのデータセンターを含むオペレーティングシステムとハードウェアのアップグレードとメンテナンスも実装していました。 セキュリティを向上させるためのプロジェクトは頻繁であり、作業量の大部分を占めていました。
オフショアのヘルプデスクは、通話待機時間の長さに悩まされていました。 重大なインシデントやサービスの停止はよくありました。 その組織は、毎週の変更諮問委員会(CAB)を利用して、運用環境に対するすべての変更を承認していました。 CIОは、変更がうまく実装されていない場合によるビジネスの中断を抑制するためにCAB に参加しました。 ほとんどの変更は営業時間外に発生し、深夜や週末の作業が発生しました。
これらの問題とは別に、スポンサーや顧客からのフィードバックからもアジリティを追求するための推進力が生じました。 多くが、インフラストラクチャ部門がプロジェクトを時間どおりに、または予算内で完了していないと感じていました。 彼らは一度に36以上のアクティブなプロジェクトを実行していました。 従業員は非常に熟練していましたが、一度に取り組んでいるプロジェクトが多すぎて手薄になっていました。
技術と知識は、特定の主要な個人(ネットワークのエキスパート、ストレージのエキスパートなど)が持ち、共有されていませんでした。 ドメインやプラットフォームの移行など、一部のプロジェクトは何年も前から進行していました。 合併や買収は予期せぬかたちで起こり、この組織はすべてを投げ出して新たなチャンスに乗り込むことになりました。 変化が激しく、効果的に適応するのに苦労しました。
最初のステップ
現状を把握したうえで、組織内をプロジェクト担当とサポート担当に分けました。 同じ人がどちらにも適応していたので、これは非常に難しいことでした。 いくつかの難しい決定を下した後、クラウドの導入に焦点を当てた、最初の部門横断的 スクラムチームを決めました。
次に、1つのバックログに優先順位をつけるという観点から、自分たちの仕事を評価することを始めました。 意識向上キャンペーンを開始し、コンセプトに関するフィードバックを集めた後、従業員やインフラ部門にとって重要である理由や潜在的な価値を誰もが理解できるようにしました。
ステークホルダーと協力して説得力のあるビジョンステートメントを作成し、それを達成するためのロードマップを組み立てました。 ロードマップには、すべての厄介な問題、技術的な課題、アップグレード、予定されている大まかなプロジェクトが追加された。 彼らはスクラム講座で学んだ価値へのロードマップを使用して、顧客とステークホルダーのために達成したい成果に焦点を当てました。
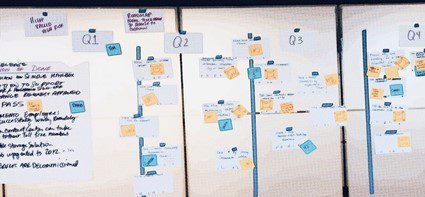
インフラストラクチャ ロードマップの最初のドラフト
中間調整
クラウド導入チームの成功に基づいて、より多くのチームを編成しました。 同社は、1のチームがコーチングを受け、予測可能なベロシティを達成してから、次のチームを編成していくことを繰り返しました。 各チームには、 プロダクトオーナー、開発チーム、スクラムマスターがいました。
チームがコラボレーションを開始し、共にリリースを計画しました。 プロダクトオーナーはチームとして作業し、事前にミーティングを行って、対処すべき主要なバックログ項目を特定し、リリース目標をドラフトしました。 チームは、スクラムマスターが進行役を務める共同リリース計画セッションに参加しました。
各チームは、リリース目標を達成するために、組み合わさったバックログから対処したい項目を選びました。 当初はチームの能力が不足していたため、実行困難でした。 しかし時間と共に能力が積み上がり、自然と容易になっていきました。 能力を構築するための鍵は、ピアレビューであることが分かりました。 作業しているチームにとって、より身近なチームがフィードバックとしてのレビューをしました。 チーム横断的にスプリントレビューに参加することは非常に重要でした。
クラウド導入のために、そのスクラムチームはクラウド・インフラストラクチャへの移行を可能にするツール作成に重点を置きました。 ツールの価値が高ければ高いほど、組織による採用が容易になりました。 それまでのように、無理矢理クラウドへ移行させられるのではなく、皆、自然にクラウドを利用し始めました。 彼らはツールが便利だと感じました。要するに、自分自身で動いたのです。
チームはまた、自分たちの仕事からすぐに利益を得ることができる特定のユーザーグループに集中しました。 たとえば、多要素認証のロールアウトでは、チームは新製品、サポート ドキュメント、およびユーザーのサブセットを使用してスプリント中に構築された自動化プロセスを試験運用しました。 彼らはユーザーをスプリントレビューに招待し、フィードバックを集めました。
フィードバック後のイテレーションに、次のユーザーのための改善として、フィードバック内容を実装しました。 Tier 2のサポート チームがスクラム チームの作業をシャドーイングし、すぐに機能をより多くのユーザーに展開できるようになり、スクラムチームは次に優先度が高いバックログアイテムに移行できるようになりました。
チームが苦労した最大のハードルは、インシデントやサービスリクエストのエスカレーションによる作業の中断でした。 当初、スクラムチームはチームメンバーを週を通して「オンコール」に指定し、スプリント計画中のメンバーの可用性を減らしました。 彼らはスプリントごとにメンバーをローテーションして、ユーザーをサポートしながら全員に学ぶ機会を持たせるようにしました。 その後、彼らはより強力なTier 2サポート組織を構築することにし、各スクラムチームからフルタイムのTier 2サポートにメンバーを移しました。
ITサポートとの連携
彼らが顧客をサポートするために使用した戦略は、トライアングル型サポートとして知られていました。
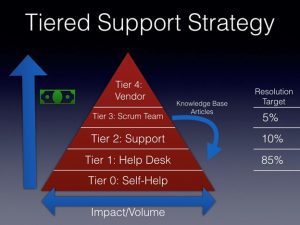
階層型サポート戦略
この一般的なサポートモデルの図は、左軸にコストを示し、下部にインシデント、問題、およびサービス要求の影響または量を示しています。 インシデントがピラミッドの上位に上がるにつれて、サポートのコストが増加しました。 Self-help(自助)が最も安価で、次にHelp Desk(ヘルプデスク)エージェントのコストが続き、より経験豊富なTier 2およびTier 3のエンジニアのコストよりも安価でした。
下部には、最大数のインシデントに対処するためのヘルプデスク人員が配属されていました。 また、24時間年中無休の対応だったため、ユーザーからの多くの問題に対処することができました。 また、幅広い人員配属モデルにより、サービスの停止や中断に、迅速に対応できるようになりました。
各層(Tier)で、解決目標を設定しています。 ヘルプデスクは、インシデントとサービスリクエストの85%を解決することを目標としていました。 Tier 2 と Tier 3 によって提供される手堅い知識ベースとトレーニングは、この目標を達成するためにとても重要でした。 ヘルプデスクがインシデントを解決できなかった場合は、上がってきたインシデントの 10% を解決することを目標とするTier 2 にインシデントをエスカレーションし、最後の 5% はTier 3のスクラム チームに託しました。 エスカレーションされたインシデントやリクエストについて、下位の階層が解決できなかった理由を評価しました。
最も困難なインシデントとリクエストである 5% に対処することで、スクラムチームは製品についてより明確な洞察を得ることができました。 高品質の製品を構築することが最重要とされたのは、戦略的な作業に混乱を招きたくなかったからです。 直接の経験は、ユーザーエクスペリエンスを理解するのに役立ちました。 ヘルプデスクとTier 2によって収集された製品に関するデータは、経験的フィードバックの重要な情報源である製品のパフォーマンスを評価するために、プロダクトオーナーにとって非常に貴重でした。
完了の定義
スクラム チームは、ナレッジ ベースの記事とトレーニングと共に、完了の定義の一部としてヘルプ デスクと階層 2 の両方からのリリース サインオフを含めました。 セルフヘルプという選択肢が当たり前になりました。 チームが、完了の定義と製品バックログアイテムの受け入れ基準を満たしていると確信しない限り、変更は運用環境にリリースされませんでした。 「完了」とは、製品のインクリメントが意図したとおりに機能するだけでなく、サポートすることができるということを意味します。
サポートトライアングル戦略では、最も多くのインシデントとサービスリクエストに対処するために、最低コストの賃金を採用しました。 また、スクラムチームを保護することで、根本原因に対処するための戦略的イニシアチブの進捗を最大化できるようにしました。 長期的には、品質が向上するにつれて、この戦略により、より多くのサポートチームメンバーが戦略的スクラムチームに有機的に移行できるようになりました。 この戦略により、組織は事後対応型から事前対応型への移行への道を歩むことができました。
インシデントのエスカレーションフロー
サポート部門として、サービスレベルアグリーメント(SLA)パラメーター内で対応する必要がありました。 サポートトライアングル戦略に従って、インシデントのエスカレーションフローを特定しました。 彼らは、発信者のニーズを満たすようにフローを設計し、スクラムチームを保護しました。 彼らは、スクラムチームの継続的な中断が納期の遅れにつながり、全員にダメージを与え、サービスの停止が収益に影響を与えることを理解していました。
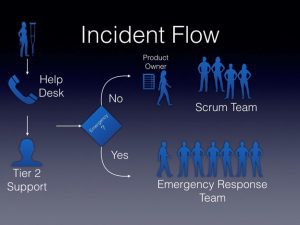
フローでは、スクラム チーム(Tier 3)にエスカレーションされたインシデントが、最初にプロダクトオーナーに回されるように設計しました。 その後、プロダクトオーナ⁰は、チームの優先順位に応じて、インシデントにその場で対処するか、後に対処するべくバックログに入れるかを決定しました。
緊急停止が発生した場合、組織は前述の緊急対応構造(Tier 1からTier 2へ) を使いました。 時にはスクラムチームのメンバーも協力しました。 インシデント後のレビュープロセスには、スクラムチームメンバーが将来的に呼び出されるのを防ぐために、下位層が必要とする知識の収集も含まれていました。
変更とリリースの管理
スクラムチームが成熟するにつれて、変更と本番環境へのリリースを管理する方法に関連する別の改善の機会を特定しました。 チームは、CABが打ち合わせをした時期に基づいてスプリントの境界を決めました。 これは、スプリント中の作業がCABによって承認されていれば遅延が軽減するためのものです。 さもなければ、週に一度しか打ち合わせをしないCABによる変更の承認を、1週間待たなければならず、緊急の変更が難しくなります。
しかし、より大きな問題は、本番環境への変更に対する責任の範囲でした。 かつてCABは、全員に説明責任を負わせるという立場をとっていました。 作業が中断した経緯があるため、彼らの同意なしに変更が承認されることはありませんでした。 CAB は、必要なアンチパターンとして認識されていました。
インフラストラクチャ部門が、自己組織化され、権限を与えられたチームと人員に基づいたアジャイルな価値観と原則を実践するにつれて、説明責任が高まりました。 早期の失敗は学習にとって重要なことであったため、チームは最もリスクが高く、最も価値のあるプロダクトバックログアイテムに最初に取り組みました。 よりエンパワメントに傾くために必要な「指揮と制御」のバランスを認識しました。
その結果、2つの変更が実装されました。 まず、スクラムチームが自分たちの確固たる完了の定義に従って、標準的な変更プロセスを使用できるように方針が変更された。 そして、標準的な変更を、失敗しないことが証明された反復可能な変更として定義しました。 これにより、プロダクトオーナーの裁量で変更を実装することができるようになりました。 次に、標準的な変更の承認権限が CABからプロダクトオーナーに移管され、承認を上層部に依存する必要がなくなりました。
次の図は、変更要求(RfC)のプロセスがスクラムフレームワークにどのようにオーバーレイされたかを示しています。 チェンジマネージャー(RfCのツールとプロセスを管理する担当者)とプロダクトオーナーが協働して、RfCの成功を確実にしました。 スクラムチームは、変更の文書化、構築とテスト、技術レビューの実行、承認の取得(ステークホルダーからのフィードバックの収集など)、変更のスケジュール設定、RfCの実装と終了を担当しました。 変更マネージャーとCABの役割は、指示的ではなく、協力的なものになりました。
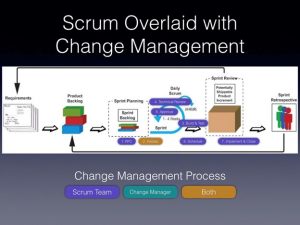
スクラムにおけるITサービス管理(ITIL)変更管理
スクラムチームは、CABのではなく、自分たちのニーズに合ったスプリントのリズムとスケジュールを選択しました。 チームは、変更によって作業が中断されないようにする責任を負うようになりました。 いくつかの中断や停止が発生しましたが、チームはそこから学び、将来の中断を防ぐために改善を行いました。 彼らは、さまざまなプロダクトオーナーとチームによるスクラムオブスクラムの自己調整が重要であることに気づきました。
主な課題
アジャイルなインフラストラクチャ部門は、多くの課題に直面します。 この部門では、強調すべき点が3つがあります。
スキルの多様性
機能横断的なインフラストラクチャ・スキルは、キャリアをやや制限していると、チームメンバーから認識される可能性があります。 ネットワーク、ストレージ、Citrixなどの人々は何年間も訓練を受け、各分野で徹底的な教育を受け、認定を取得します。 実行する必要のあるタスクであれば何でも実行することが期待される部門横断的なチームにいることを余儀なくされると、彼らの抵抗に遭う可能性があります。
ソフトウェア開発チームのメンバーについても同じことが言えます。 チームメンバーとキャリアの願望について率直に話すことで、この緊張を和らげることができますが、それでも困難は残ります。 チームのベロシティは能力の関数であり、単一障害点はリスクがあることを全員に思い出させてください。
継続的なサポート
前述のように、インフラストラクチャ部門の多くは、アップグレードの実行や新しいサービスの実装だけでなく、既存のインフラストラクチャを維持し、ユーザーが経験した問題を解決する必要もあります。 サポートのために優先度の高い作業から継続的に引き抜かれることは、インフラストラクチャスクラムチームにとって苛立たしく困難な場合があります。 製品の改善を、短期的なものと長期的なものでバランスをとることができる、強く、決断力のあるプロダクトオーナーは、こういった懸念に大きく役立ちます。
有能なサポート
最後に、セルフヘルプに焦点を当て、すべてのインシデントとサービスリクエストの85%を解決できるヘルプデスクを築く戦略を構築することは困難です。 全員が協調し、集中し、規律ある努力をすることが必要です。 ステークホルダーとのスプリントレビュー監査とチームのレトロスペクティブは重要です。
結果
このインフラストラクチャ部門は多くの成功を収めました。 ヘルプデスクとTier 2は組織的な能力を向上させ、開発チームのメンバーの能力も向上しました。 特定のスキルを持つ人は、そうでない人を教えました。 スクラムチームは、自然と、新しいスキルを学び、駆使するためのインキュベーターでした。
単一障害点は完全には除去されませんが、減少しました。 さらに良いことに、何人かのスクラムチームメンバーには、新しく学んだスキルを活用して新しいキャリアの機会が与えられました。T字型の人材と T字型のチーム(1 つの分野では強力なスキルがあるが、多くの分野に触れ、能力を発揮できる)が生まれ、ビジネス上のアジリティがさらに向上しました。
チームは、製品の納品を改善する権限を与えられました。 彼らは早期かつ頻繁に変更をリリースしました。 チームは、CABではなく、自分たちのニーズに合ったスプリントのリズムとスケジュールを選択しました。 サーバントリーダーシップは、批判やコントロールではなく、サポートをする方法を模索するリーダーとともに拡大しました。 夕方と週末の仕事は減少しました。 アーキテクチャはより弾力的になり、むしろ創発的でもあり、そのことによって営業時間中に変更を加えることができました。 全体として、インシデントと停止は減少しました。
最後に、進行中の作業が大幅に減り、最優先の作業をより迅速に完了できるようになりました。 チームメンバーは優先順位に集中でき、バタバタすることが少なくなりました。 この組織では、進行中のプロジェクトの数が36から3になりました。 CIOとの最新情報の共有は、ほとんどの時間を「進行中」の作業に費やすことから、実際に完了した作業へと移行しました。 短いスプリントと頻繁なリリースにより、急な合併や買収はバックログの一番上に移動させればよくなりました。
アジャイルなインフラストラクチャは有利です
ビジネス上のアジリティを高めることは、ソフトウェアのためだけではありません。 インフラストラクチャにもメリットがあります。 インフラストラクチャのアジリティを高めるための鍵は、ソフトウェアの場合と同じです。 価値へのロードマップを使用し、確固たる完了の定義を堅持し、継続的に監査して適用します。 永続的で、小規模で、やる気があり、自己組織化され、部門横断的で、同じ場所に配置された(近接した)スクラムチームを構築しましょう。 必要な環境とサポートを提供し、彼らが仕事を成し遂げるために信頼しましょう(アジャイルの原則5)。
ぜひご相談ください。 トレーニング、採用、変革のお手伝いをします!