




Many associate agile product development primarily with software development. That’s because the agile manifesto and principles specifically reference “software.” However, agile values and principles can apply more broadly. People use agile approaches to create products in a variety of industries, from biotech to manufacturing to marketing. They can do this because they have an agile infrastructure. In this article, we’ll discuss how an infrastructure department became more agile using scrum.
The background and challenges
Like many infrastructure departments, this one managed the services offered to employees and customers (hardware, software, network, storage, etc.) and were responsible for technical support. Typical projects ranged from cloud migration to network and storage upgrades to deploying multi-factor authentication. They also implemented upgrades and maintenance of operating systems and hardware, including on and offsite data centers. Projects to improve security were frequent and a large portion of their workload.
The offshore help desk suffered from long call wait times. Major incidents and service outages were common. The organization used a weekly Change Advisory Board (CAB) to approve all changes to production. The CIO joined the CAB to curb business disruption from poorly implemented change. Most changes occurred during non-business hours, causing late evening and weekend work.
Aside from these issues, the drivers for pursuing agility stemmed from the feedback from their sponsors and customers. Many felt the infrastructure department never completed a project on time or within budget. They had 36 active projects or more running at any one time. Their employees were very skilled but were spread thin, working on multiple projects at once.
Skills and knowledge lived in silos with specific key individuals (network expert, storage expert, etc.). Some projects, such as domain or platform migrations, were in progress for years. Mergers and acquisitions arose somewhat unexpectedly, causing the organization to drop everything to onboard the new opportunity. Change was rampant, and they struggled to adapt effectively.
Initial steps
After an assessment of their current state, they separated the organization into project people and support people. This was particularly difficult because many of the same people were both. After making some difficult decisions, they defined their first cross-functional scrum team focused on cloud adoption.
Second, they started evaluating their work from the perspective of prioritization into a single backlog. After initiating an awareness campaign and collecting feedback on the concept, they helped everyone see the potential value and reasons why it would be important for employees and the infrastructure department.
They collaborated with stakeholders to build a compelling vision statement and assembled a roadmap to accomplish it. The added all nagging problems, technical challenges, upgrades, and planned projects at a high level to the roadmap. They used the Roadmap to Value learned in scrum class, focusing on the outcomes they wanted to achieve for their customers and stakeholders.
The first draft of the Infrastructure Roadmap.
Intermediate adjustments
Building on the success of the cloud adoption team, they created more teams. The company organized teams one by one, but not before earlier teams received coaching and achieved a predictable velocity. Each team had a product owner, development team, and a scrum master.
As the teams started collaborating, they planned their releases together. Product owners worked as a team and met beforehand to identify key backlog items to address and draft the release goal. The teams joined the conversation for a joint release planning session, facilitated by the scrum masters.
Each team pulled from the combined backlog items they wanted to address to accomplish the release goal. This “pulling” was difficult, initially due to a lack of team capability. Over time, it became easier organically as capability was built. They found that a key to building this capability was peer reviews. The more familiar team reviewed the work by the team pulling it for feedback. Cross-team sprint review participation was critical.
For cloud adoption, the scrum team focused on making tools that enabled moving to the cloud infrastructure. The more valuable the tool, the more readily the organization adopted it. Instead of forcing or pushing everyone to move to the cloud, as they would have done in the past, people started using it naturally. They found the tools useful; in essence, they moved themselves.
The teams also concentrated on specific user groups that would receive immediate benefit from their work. For the multi-factor authentication rollout, for example, the team piloted their new product, support documentation, and automated processes built during the sprint with a subset of users. They invited the users to their sprint review and gathered their feedback.
They implemented the feedback in the next iteration as improvements for the next set of users. The Tier 2 support team shadowed the scrum team’s work and soon became capable of rolling the features out to a wider audience, allowing the scrum team to move to the next priority backlog item.
The biggest hurdle the teams struggled with was disruption to their work caused by escalated incidents and service requests. Initially, the scrum teams designated team members to be “on call” throughout the week and reduced that person’s availability during sprint planning. They rotated individuals each sprint to ensure everyone had the opportunity to learn as they supported users. Later, they decided to build a stronger Tier 2 support organization and moved members from each of the scrum teams to become full-time Tier 2 support.
Alignment with IT support
The strategy they used for supporting customers was known as the Support Triangle.
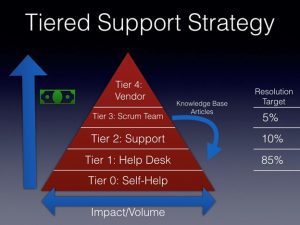
Tiered support strategy
This common support model diagram shows cost on the left axis with impact or volume of incidents, problems, and service requests across the bottom. The cost of support increased as the incident escalated higher up the pyramid. Self-help was least expensive, followed by the cost of the help desk agent, which was less expensive than the cost of the more experienced Tier 2 and Tier 3 engineers.
Across the bottom, the Help Desk was staffed to address the largest volume of incidents. They were also able to address many issues from users since they were available 24×7. Their broad staffing model also allowed them to respond quicker to outages or service disruptions.
Each tier set a resolution target. The Help Desk targeted to resolve 85% of the incidents and service requests. A robust knowledge base and training provided by Tier 2 and Tier 3 were critical for hitting this goal. If the Help Desk couldn’t resolve the incident, they escalated to Tier 2 that had a target to resolve 10% of the escalated incidents, leaving the last 5% for the Tier 3 scrum team. Evaluation of each escalated incident or request for reasons lower tiers were unable to resolve it occurred.
Addressing the most challenging 5% of incidents and requests gave scrum teams clearer insight into their products. Building quality products became paramount because they didn’t want disruption to their strategic work. First-hand experience helped them understand the user experience. The data collected about the product by the Help Desk and Tier 2 was extremely valuable to the product owner for evaluating their product’s performance, a key source of empirical feedback.
Definition of done
Scrum teams included release sign-off from both the Help Desk and Tier 2 as part of their definition of done, along with knowledge base articles and training. Self-help alternatives became the standard. Changes were not released to production unless the team was confident they had fulfilled their definition of done and the acceptance criteria of the product backlog item. “Done” meant the product increment would not only function as intended but could also be supported.
The Support Triangle strategy used the lowest cost wages to address the largest number of incidents and service requests. It also shielded the scrum team, enabling them to maximize progress on strategic initiatives to address root causes. Longer-term, as quality improved, this strategy enabled more of the support team members to shift organically to strategic scrum teams. The strategy placed the organization on a path to move from reactive to proactive.
Incident escalation flow
As a support department, they needed to respond within the service level agreement (SLA) parameters. Following their Support Triangle strategy, they identified an incident escalation flow. They designed the flow to meet the needs of the caller and shield the scrum team. They understood that continual disruptions to the scrum team hurt everyone because of lost delivery, and service outages affected revenue.
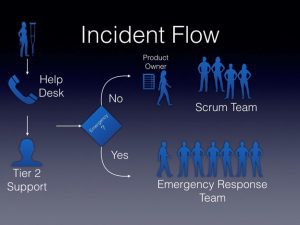
The flow defined that escalated incidents to the scrum teams (Tier 3) were directed to the product owner first. The product owner then decided to address the incident then or put it on the backlog for later, depending on the team’s priorities.
When an emergency outage occurred, the organization used their emergency response structure (Tier 1 to Tier 2) discussed earlier. At times, scrum team members helped. The post-incident review process included capturing knowledge needed by the lower tiers to prevent scrum team members from being called upon in the future.
Change and release management
As the scrum teams matured, they identified another improvement opportunity relating to how they managed change and releases to production. Teams established their sprint boundaries based on when the CAB met. They did this so they could ensure work during the sprint was approved by the CAB, thus reducing delays. Without this, they would have to wait an additional week for changes, as the CAB met only weekly, and emergency changes were discouraged.
The bigger issue, however, was accountability for the change to production. The CAB previously positioned themselves to hold everyone accountable. No changes were approved without their consent because of the history of business disruptions. The CAB was perceived as a necessary anti-pattern.
Accountability increased as the infrastructure department practiced agile values and principles founded on self-organized, empowered teams and people. Early failure was critical for learning, so the teams tackled the riskiest and most valuable product backlog items first. They realized the balance of “commanding and controlling” needed to lean more towards empowerment.
Two changes were implemented as a result. First, the policy was changed to allow scrum teams, who followed their robust definition of done, to use the standard change process. They defined a standard change as a repeatable change that had proven to not fail. This allowed the changes to be implemented at the product owner’s discretion. Second, approval authority for standard changes was transferred from the CAB to the product owner, removing the dependence on upper management for approvals.
The following image shows how the request for change (RfC) process was overlaid on the scrum framework. The Change Manager (the person managing the RfC tool and process) and the product owner collaborated to ensure the RfCs success. The scrum team was accountable for documenting the change, building and testing, performing the technical review, gaining approval (gathering feedback from stakeholders, etc.), scheduling the change, and implementing and closing the RfC. The Change Manager and CAB roles became more supportive than directive.
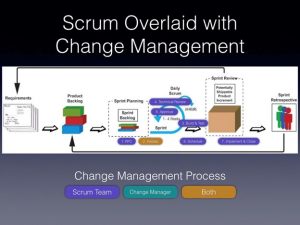
IT Service Management (ITIL) Change Management in Scrum
Scrum teams chose a sprint cadence and schedule that fit their needs rather than the CAB’s. The team became accountable for ensuring the business was not disrupted by their changes. Some disruptions and outages occurred, but the teams learned from them and made improvements to prevent future disruptions. They found scrum of scrum self-coordination between the various product owners and teams to be critical.
Key challenges
Agile infrastructure departments face many challenges. For this department, there are three to highlight.
Skill versatility
Cross-functional infrastructure skills can be perceived by team members as somewhat career limiting. Network, storage, Citrix, etc. people train for years and obtain in depth education and certifications in those areas. Telling them to be on a cross-functional team where they are expected to perform whatever task needs to be performed can be met with resistance.
The same argument can be made for a software development team member. Talking openly about career aspirations with team members can ease this tension, but it’s challenging, nonetheless. Remind everyone that team velocity is a function of capability and that single points of failure are risky!
Continuous support
As evidenced earlier, many in infrastructure departments are not only required to perform upgrades or implement new services, but they also are required to maintain the existing infrastructure as well as resolve any problems experienced by users. Continually being pulled from higher priority work for support can be frustrating and challenging for infrastructure scrum teams. Strong, decisive product owners, able to balance between short-term and long-term product improvements help significantly with this concern.
Capable support
Lastly, the strategy of focusing on self-help and building a help desk that can resolve 85% of all incidents and service requests is difficult to build. Concerted, focused, and disciplined effort by everyone is required. Sprint review inspections with stakeholders and team retrospectives are critical.
Outcomes
This infrastructure department experienced many successes. Their Help Desk and Tier 2 organization’s capability increased, and the capability of the development team members increased, as well. Those with a particular skill taught those without. The scrum teams were natural incubators for learning and using new skills.
Single points of failure, while not completely removed, decreased. Even better, several scrum team members were given opportunities for new career paths leveraging their newly learned skills. T-shaped individuals and T-shaped teams (strong skills in one discipline, but exposure and capability in many disciplines) were created providing even more business agility.
Teams were empowered to improve their product delivery. They released changes early and often. The teams chose a sprint cadence and schedule that fit their needs rather than the CAB’s. Servant leadership expanded with leaders looking for ways to help, rather than to criticize and control. Evening and weekend work decreased. The architecture became more resilient, even emergent, allowing changes to be made during business hours. Overall, incidents and outages decreased.
Lastly, work in process reduced significantly enabling faster completion of top priority work. Team members were able to focus on priorities and had less thrashing. The organization went from 36 active projects to 3. The executive updates with the CIO shifted from spending most of the time on “in progress” work to what was actually completed. With short sprints and frequent releases, urgent mergers and acquisitions simply moved to the top of the backlog.
An agile infrastructure is advantageous
Creating more business agility is not just for software. Infrastructure can also benefit. The keys for creating more agility in infrastructure are the same as with software. Use the Roadmap to Value, hold fast to your robust definition of done and continually inspect and adapt. Build enduring, small, motivated, self-organizing, cross-functional, and co-located (co-proximity) scrum teams. Give them the environment and support they need, then trust them to get the job done (agile principle 5).